

Enhancing resiliency in opensearch clusters: An in-depth technical exploration of Admission Control
Admission control in OpenSearch helps keep clusters stable by limiting incoming requests when nodes are under heavy load. Atlassian saw improved search reliability after enabling this feature, especially during traffic spikes.
Atlassian recently introduced a new product Rovo that targets to help teamwork with AI teammates.
Atlassian search platform is a common platform that empowers whole Atlassian search across all it’s own products and integrate third party products. In fact, Rovo is also empowered through search platform. Atlassian’s search platform processes billions of requests every day. Such a massive scale can easily put a strain on OpenSearch, potentially leading to search performance degradation. To mitigate these issues, opensearch implements various rejection mechanisms designed to manage in-flight requests and new requests when the cluster is under heavy load. Key control mechanisms currently available are shard indexing backpressure, search backpressure, and circuit breakers, contribute significantly to enhancing cluster reliability.

In this article, we will explore admission control, a feature introduced in opensearch version 2.13.0, and examine how it can bolster the reliability of opensearch clusters and help provide better search reliability.
Indexing and search are two critical features in opensearch. At times, high indexing or search requests or sudden spike in such requests could lead to performance degradation. Admission control enhance the resiliency by rate limiting incoming requests at rest layer, when node is under high stress.
OpenSearch Release update: https://github.com/opensearch-project/opensearch-build/blob/main/release-notes/opensearch-release-notes-2.13.0.md
Why Admission Control?
The admission control framework rejects incoming requests based on the resource utilisation statistics of the nodes. This allows for real-time, state-based admission control on the nodes. By regulating the flow of operations into the cluster, admission control mechanisms help prevent resource contention and ensure the system operates within its capacity, thereby mitigating the risks associated with overloading.
What is Admission Control ?
The admission control settings in OpenSearch are designed to manage how system resources are allocated to search and indexing operations, particularly under conditions of resource contention. Admission control acts as a gatekeeping mechanism that proactively limits the number of requests to a node based on its current capacity, accommodating both organic increases and spikes in traffic. These settings help ensure that cluster performance remains stable, even when demand for resources is high.
It tracks each node’s rolling average CPU usage and IO usage to reject incoming search and bulk requests. This prevents nodes from being overwhelmed with excessive requests, which can lead to hotspots, performance issues, request timeouts, and other cascading failures. Excessive requests will return an HTTP 429 “Too Many Requests” status code upon rejection.
Technical Breakdown
By default, admission control configuration is disabled. You can simply check it by hitting cluster settings API (Make sure to include defaults)
Settings API endpoint:
GET _cluster/settings?include_defaultsResponse:
"defaults": {
"admission_control": {
"cluster": {
"admin": {
"cpu_usage": {
"limit": "95"
}
}
},
"search": {
"cpu_usage": {
"limit": "95"
},
"io_usage": {
"limit": "95"
}
},
"transport": {
"io_usage": {
"mode_override": "enforced"
}
},
"indexing": {
"io_usage": {
"limit": "95"
}
}
}
}
Admission control has three levels of modes i.e.
- DISABLED
- MONITOR
- ENFORCED
By default, this configuration is disabled. In the MONITOR mode, the admission control service will check each incoming request but will not cancel any; it will only monitor them. You can review monitoring statistics for each node using the node stats API. Conversely, the ENFORCED mode allows OpenSearch to reject any incoming requests that exceed the established limits.
Check for opensearch code references here.
Enable admission control
There are three levels of control that we need to enable before we start using this control mechanism.
- First level control – Enable admission control
PUT _cluster/settings
{
"persistent":{
"admission_control.transport.mode": "disabled"/"monitor"/"enforced"
}
}- Second level control – Enable CPU/IO based admission control
PUT _cluster/settings
{
"persistent":{
"admission_control.transport.cpu_usage.mode_override": "disabled"/"monitor"/"enforced"
}
}
PUT _cluster/settings
{
"persistent":{
"admission_control.transport.io_usage.mode_override": "disabled"/"monitor"/"enforced"
}
}- Third level control – Set desired limit for CPU / IO usage for indexing/search requests
// indexing limits
PUT _cluster/settings
{
"persistent":{
admission_control.transport.indexing.cpu_usage.limit = 90
}
}
PUT _cluster/settings
{
"persistent":{
admission_control.transport.indexing.io_usage.limit = 90
}
}
// search limits
PUT _cluster/settings
{
"persistent":{
admission_control.transport.search.cpu_usage.limit = 90
}
}
PUT _cluster/settings
{
"persistent":{
admission_control.transport.search.io_usage.limit = 90
}
}In case of limit breach, admission control reject the requests with 429 error. Sample rejection response:
{
"took": 0,
"errors": true,
"items": [
{
"index": {
"_index": "my-index",
"_id": "1",
"status": 429,
"error": {
"type": "rejected_execution_exception",
"reason": "CPU usage admission controller rejected the request for action [indices:data/write/bulk[s][p]] as CPU limit reached for action-type [INDEXING]"
}
}
},
{
"index": {
"_index": "my-index",
"_id": "12",
"status": 429,
"error": {
"type": "rejected_execution_exception",
"reason": "CPU usage admission controller rejected the request for action [indices:data/write/bulk[s][p]] as CPU limit reached for action-type [INDEXING]"
}
}
}
}Indexing node stats API depicting indexing failure. (Rejection count – 3078)
{
"_nodes": {
"total": 1,
"successful": 1,
"failed": 0
},
"cluster_name": "docker-cluster",
"nodes": {
"B8Vyy4a_xxxxxxxxxxxx": {
"timestamp": 1733926534581,
"name": "5e762c4eb3f9",
"transport_address": "172.20.0.11:9300",
"host": "172.20.0.11",
"ip": "172.20.0.11:9300",
"roles": [
"cluster_manager",
"data",
"ingest",
"remote_cluster_client"
],
"attributes": {
"shard_indexing_pressure_enabled": "true"
},
"admission_control": {
"global_io_usage": {
"transport": {
"rejection_count": {}
}
},
"global_cpu_usage": {
"transport": {
"rejection_count": {
"indexing": 3078
}
}
}
}
}
}
}It is important to note that all rejected requests represent actual customer data that must be indexed in due course. The system should be sufficiently robust to manage these rejection scenarios effectively. There are potentially various approaches to address this issue. One viable method would be to retry processing all messages a specified number of times before ultimately transferring them to a Dead Letter Queue (DLQ).

How Atlassian benefited from using admission control ?
- Before admission control was enabled
Let me give you an example where there was surge in indexing events within short span of time and how it impacted search latency


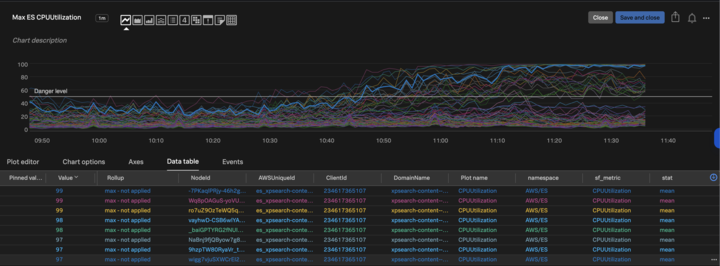

As it can be seen through the graph, CPU usage on impacting OS data nodes almost reached ~100% due to which search was impacted. It can be seen through search reliability graph.
2. Post admission control enablement
Admission control targets bringing stability to the search reliability even with high indexing load.



As it can be seen through the graph, search reliability doesn’t degrade with increasing surge in traffic.
Conclusion
Admission control is a cornerstone of robust and resilient opensearch clusters, providing the necessary control mechanisms to manage resource utilisation and ensure consistent performance. By implementing technically sound and strategically configured admission control policies, organisations can effectively handle increasing data volumes and complex query patterns.
For those looking to refine their admission control strategies, the insights and methodologies discussed here offer a foundation for building more resilient and efficient OpenSearch deployments. By embracing these advanced technical practices, engineers can ensure their systems are well-prepared to meet future demands while maintaining optimal performance and reliability.
As we continue to explore and refine these techniques, the potential for optimising distributed systems grows, promising a more robust and responsive future for data-intensive applications. For further technical details and experimental setups, I encourage you to review the internal documentation linked in this post, which provides a comprehensive guide to implementing and fine-tuning admission control in your OpenSearch environments.