





Atlassian’s Inference Engine, our self-hosted AI inference service
Powering Enterprise-scale AI
As Atlassian’s AI capabilities continue to scale rapidly across multiple products, a pressing challenge emerged: how do we deliver world-class AI-powered solutions to millions of users without compromising on latency, flexibility, and operational control?
The answer: Atlassian’s Inference Engine, our custom-built, self-hosted AI inference platform that now powers production LLMs, search models, content moderators, and more across the Atlassian Cloud.
With it, we’ve achieved:
- ⚡ Latency Improvements for LLM and non-LLM workloads:
- For LLM workloads (apples-to-apples comparison moving from 3rd party hosting to Atlassian’s Inference Engine) we’ve observed up to 40% P-90 latency reduction at scale.
- For non-LLM workloads on an apples-to-apples comparison, we have observed up to 63% P-90 latency reduction at scale.
- 💸 Cost Savings for LLM and non-LLM Workloads
- For LLM workloads, infrastructure migration from 3rd party to hosting on Atlassian’s Inference Engine, we’ve observed >60% cost reduction.
- For non-LLM workloads, infrastructure migration from 3rd party to hosting on Atlassian’s Inference Engine, we’ve observed >80% cost reduction.
- 🔍 Enhance observability and debugging at every layer
- 🚀 Rapid iteration and support for models across architectures
Why We Built It
Off-the-shelf solutions got us off the ground, but as usage scaled and product teams demanded more control, bottlenecks became unavoidable:
- Latency that didn’t meet our SLOs
- Rigid deployment experience
- Vendor lock-in and hard to troubleshoot
- Pricing that didn’t match our optimization goals
So we built a solution from first principles. The Atlassian Inference Engine isn’t a proof-of-concept, it’s a foundation in how we ship AI at Atlassian.
Technical Challenges & Early Concerns
Building our own inference platform wasn’t a decision we took lightly, we knew we’d be taking ownership of everything from optimization and performance to uptime and cost control, and we had real concerns going in.
Some of the early challenges and questions we asked ourselves included:
- How can we scale inference and still manage cost with performance?
- What tools can help us experiment and iterate faster?
- How do we make sure our performance meets the bar for latency and throughput?
- Can we make open-source models competitive in terms of performance and quality of proprietary models delivered through third-party APIs?
- What sort of approaches can we take in the design to allow our team to scale output?
Architecture Overview
Atlassian’s Inference Engine is built on a foundation of open-source technologies, with internal systems layered in to support enterprise-grade AI workloads. This initiative laid the groundwork for AI workloads on KITT (Atlassian’s internal Kubernetes platform).
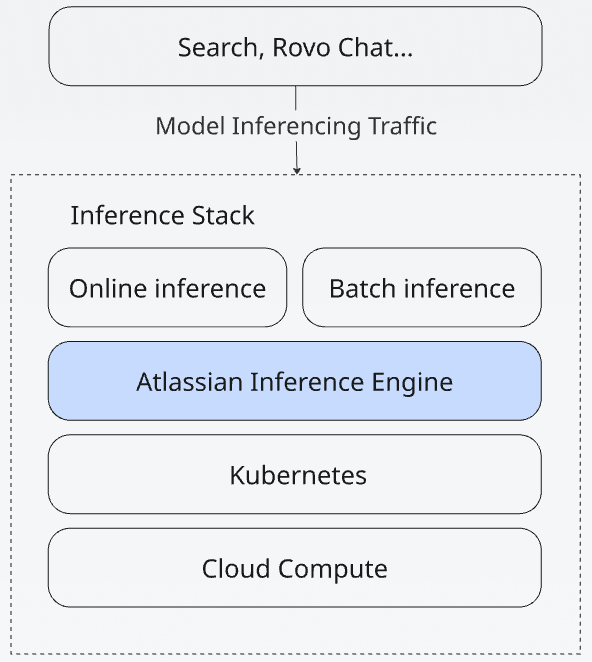
Under the hood, Atlassian’s Inference Engine runs on a modern, cloud-native stack:
- Kubernetes – the backbone for container orchestration
- Karpenter – for dynamic provisioning of nodes based on real-time demand
- ArgoCD – enabling GitOps-style deployment workflows and declarative infrastructure management
- Helm – for parameterized and version-controlled model deployments.
This stack allows us to fully automate cluster provisioning, model rollouts, and versioning, and gives us fine-grained control over GPU spend, rollout safety, and operational observability without being locked into a proprietary platform.
We designed Atlassian’s Inference Engine to scale our impact. That meant investing early in designing for automation and clean interfaces between systems. This mindset has helped us support dozens of models in parallel, optimize for cost performance, and move fast without compromising reliability.
Deployment Model: GitOps for Reliability and Traceability
We use a Git-based deployment model for everything from system configurations to model deployments. Each environment is managed via declarative manifests stored in Git, with ArgoCD continuously reconciling the desired state.
This approach gives us:
- Full version control over every change to infrastructure and model rollout
- Auditable, reproducible deployments across staging and production
- Safer rollbacks through atomic Git-based diffs
- Clear separation of config vs runtime concerns
Our Git deployment approach also reduces human error and simplifies collaboration, proposed changes are brought up through PRs, validated with CI, and roll out safely through Git merges. This model gives our team confidence in how we scale inference across regions, models, and versions.
Optimization Stack
For model inferencing and optimization, our go-to setup is NVIDIA Triton Inference Server, and for GenAI models, we use TensorRT-LLM and vLLM as backends. These tools have allowed us to realize impactful latency reductions at scale, with open-source setups, and have the flexibility to deploy a wide array of AI solutions. Here are some key optimization benefits:
- Triton Inference Server gives us the flexibility to deploy a variety of models, everything from search to LLM.
- With the Triton Inference Server we run gRPC communications for our setups, providing significant performance improvements.
- Client-side tokenization is heavily encouraged for users as it separates CPU workloads from the GPU and allows our service to talk in terms of protobuf and tokens. This renders our system agnostic to client-side code libraries, allowing for seamless product team integration.
- Our in-house optimization techniques and enablement of customization on TensoRT-LLM have given us boosts in performance for latency and throughput.
- For example: We’ve seen internal LLM workloads for query rewriting having up to 72% latency reductions while maintaining performance at higher load and scale, this was accomplished through a combination of model sizing, instance sizing, gRPC enablement, client-side tokenization, and leveraging the Triton/TensorRT-LLM stack on our infra.
- The customizability of Triton and TensorRT-LLM together has allowed us to experiment and iterate on various performance settings, compilation approaches, and batching techniques to tune our configurations for the wide array of deployments we facilitate.
- vLLM has shown great performance for batching as well as granting the ability to facilitate at run-time deployments and deploy new models as they’re released.
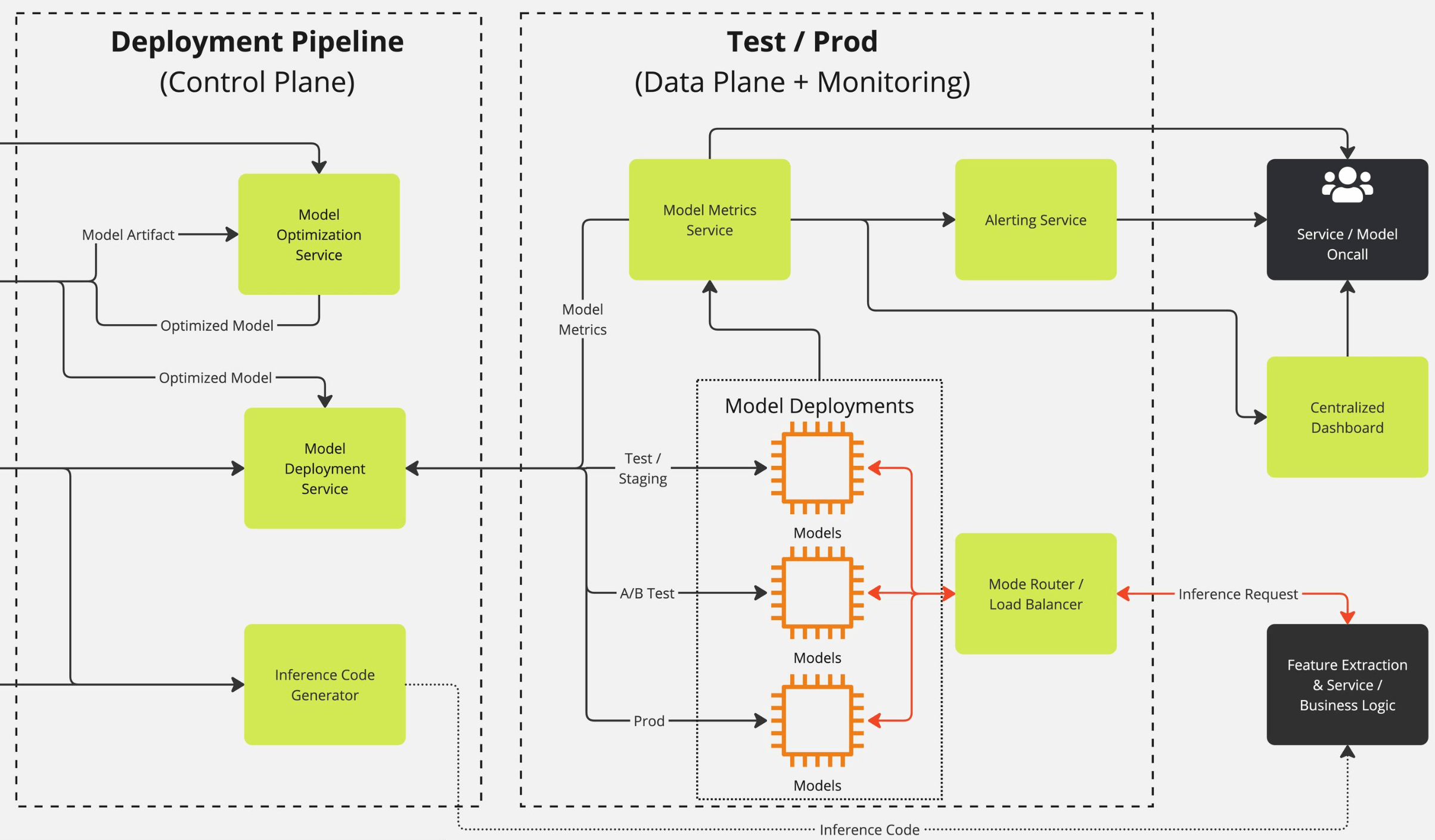
This high-level diagram outlines the structure of Atlassian’s Inference Engine, showing the split between the Control Plane, where models are prepared and optimized, and the Data Plane, where inference happens at scale.
Control Plane – Preparing the Models
Once model artifacts are uploaded to our internal registry:
- The Optimization Service compiles and tunes them
- It’s fully automated, GPU-provisioned using Karpenter
- Supports parallel, concurrent optimizations at scale
- Output models are tested and benchmarked for deployment readiness
We’re also experimenting with benchmarking different compilation strategies and broader container support.
Data Plane – Serving Inference at Scale
- Helm + ArgoCD + Kustomize – We use Helm for parameterized, templated deployments, Kustomize for overlaying environment-specific configs, and ArgoCD for continuous GitOps-based reconciliation. With this setup we have fine-grained control and reusable templates. Alternatives like FluxCD or plain YAML + CI pipelines were considered, but did not offer the same depth, control, auditable processes, and operational fit.
- Karpenter – The Atlassian Inference Engine uses Karpenter for node provisioning. Compared to alternatives like Cluster Autoscaler (which requires pre-defined node groups and scales more conservatively), Karpenter offers faster provisioning, and flexible instance selection. This is especially important for LLM workloads running on heterogeneous GPU types, where minimizing idl GPU time and reacting to increasing traffic directly impacts performance and cost. Karpenter’s dynamic, pod-driven design makes it a great fit for Atlassian’s Inference Engine.
- Istio ingress routing to distribute traffic across GPU nodes. While lighter-weight alternatives like Linkerd and NGINX ingress exist, Istio gave us better control over retries, observability, and some more advanced routing approaches like splitting traffic and shadow deployments.
- KEDA – enables austoscaling based on custom metrics (queue duration, latency, GPU utilization). Compared to HPA or custom cron-based scale-ips, KEDA gave us a clean integration path with Prometheus metrics.
- Prometheus + SignalFx for fine-grained observability into latency, GPU saturation, batching health, and request failures.
This setup lets us run resilient inference, tightly optimized for cost and performance.
Results
Today, Atlassian’s Inference Engine:
- Serves inference for critical production workloads daily
- Powers models across the Rovo AI suite including search, chat, and safety
- Replaced vendor inference with custom infrastructure and full observability
- Enables rapid iteration, self-service model deployment, and regionally optimized scaling
- Observability and monitoring system that gives us insight into hardware and inference analytics to tune for performance.
We monitor and alert on:
- Latency tracked per model
- Throughput to detect saturation or drift
- GPU utilization and memory pressure to guide autoscaling and capacity planning
- Model-level error rates and inference failures
- Keda autoscaling behavior and queue depth, queue time is a common scaling factor for our deployments.
- Batching efficiency and request queue lag to prevent throughput regressions
These metrics are surfaced through Prometheus, and we alert on the autoscaling, pod disruptions, deployment interruptions, and subnet saturation.
What’s Next
Inference at Atlassian is an evolving discipline, and we’re just getting started. Looking ahead, our focus is on improved smart scaling, deeper optimizations, and supporting an even broader range of AI use cases across products.
We’re continuing to innovate and invest in:
- Improving runtime efficiency and cost-awareness across workloads
- Expanding support for emerging model architectures and modalities
- Enhancing observability and automation in our inference pipeline
- Strengthening deployment flexibility across regions and products